Safe Multi-agent Reinforcement Learning with Natural Language Constraints
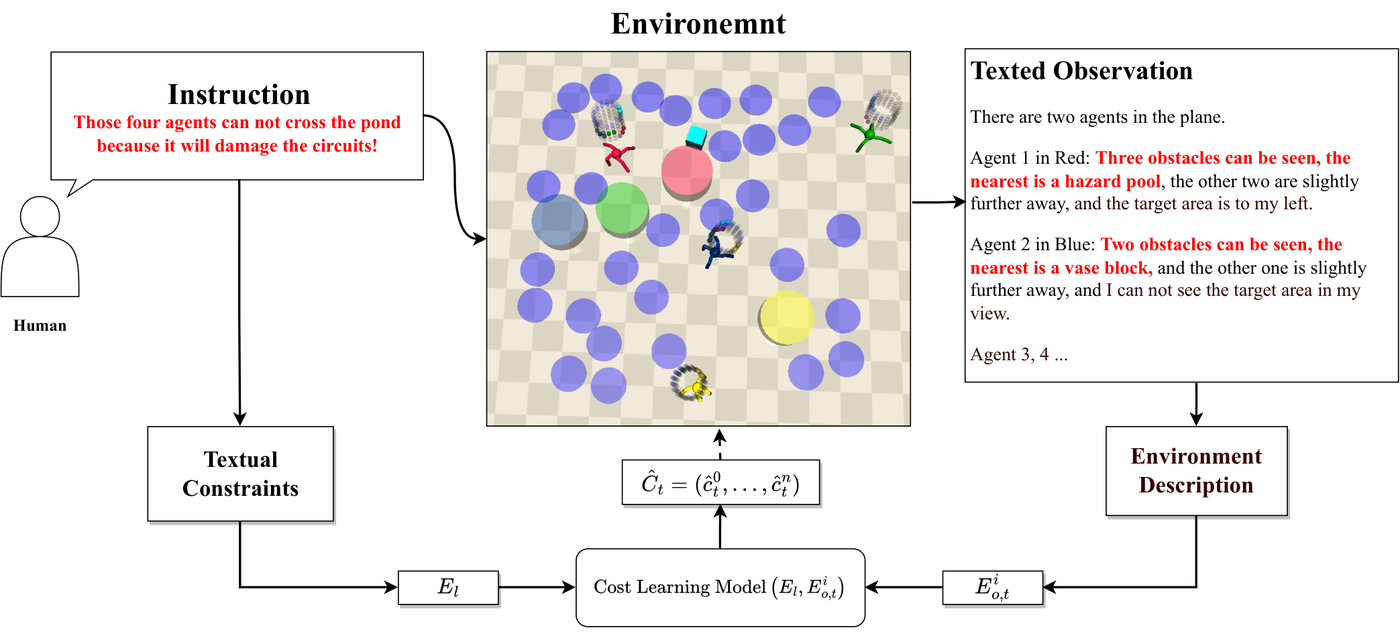
The role of natural language constraints in Safe Multi-agent Reinforcement Learning (MARL) is crucial, yet often overlooked. While Safe MARL has vast potential, especially in fields like robotics and autonomous vehicles, its full potential is limited by the need to define constraints in pre-designed mathematical terms, which requires extensive domain expertise and reinforcement learning knowledge, hindering its broader adoption. To address this limitation and make Safe MARL more accessible and adaptable, we propose a novel approach named Safe Multi-agent Reinforcement Learning with Natural Language constraints (SMALL). Our method leverages fine-tuned language models to interpret and process free-form textual constraints, converting them into semantic embeddings that capture the essence of prohibited states and behaviours. These embeddings are then integrated into the multi-agent policy learning process, enabling agents to learn policies that minimize constraint violations while optimizing rewards. To evaluate the effectiveness of SMALL, we introduce the LaMaSafe, a multi-task benchmark designed to assess the performance of multiple agents in adhering to natural language constraints. Empirical evaluations across various environments demonstrate that SMALL achieves comparable rewards and significantly fewer constraint violations, highlighting its effectiveness in understanding and enforcing natural language constraints.