
Ziyan Wang
Ph.D. Candidate · Cooperative AI Lab · King's College London
Email: ziyan.wang[at]kcl[dot]ac[dot]uk
Research overview
I am a fourth-year Ph.D. candidate at the Cooperative AI Lab, King's College London, supervised by Dr Yali Du and Prof. Sanjay Modgil. My work studies how learning agents can coordinate, communicate, and act safely in complex environments.
My central question is how to distill executable policies from human knowledge. Human knowledge appears as thinking patterns, direct instruction, books, and collective behavior; my work asks how learning agents can turn these media into robust decision-making policies.
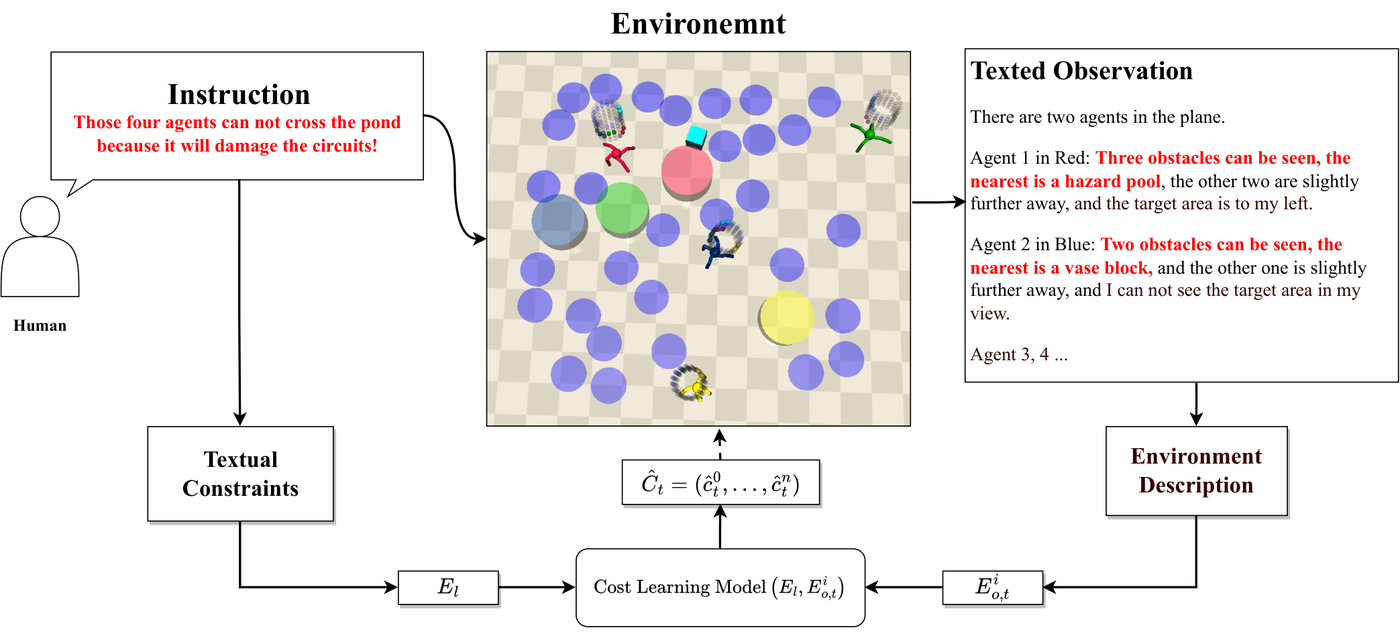
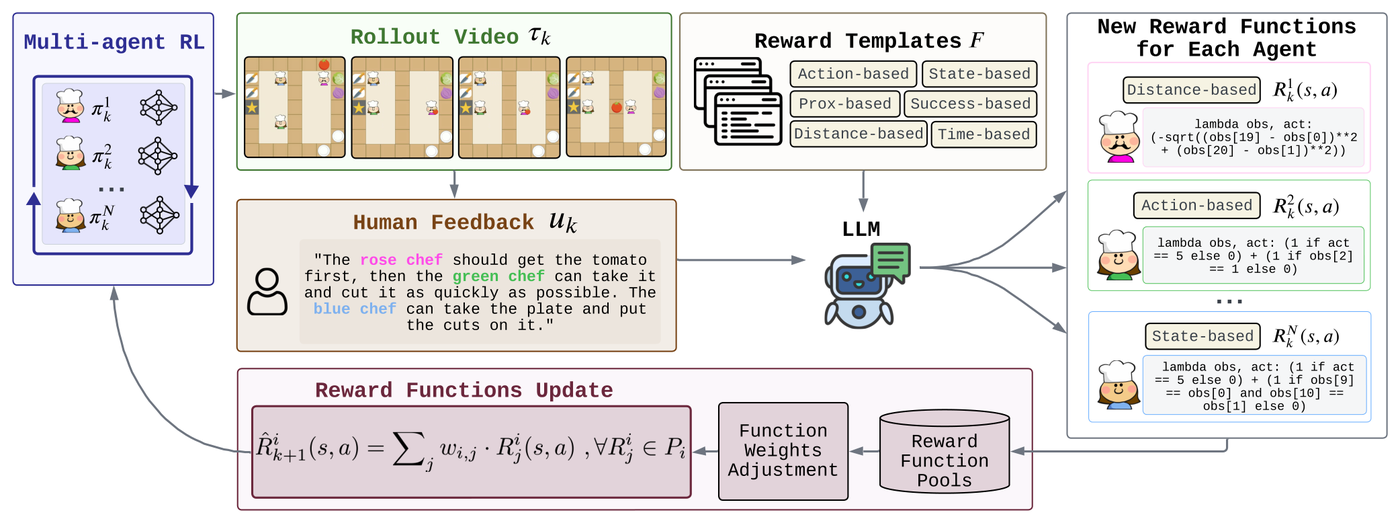
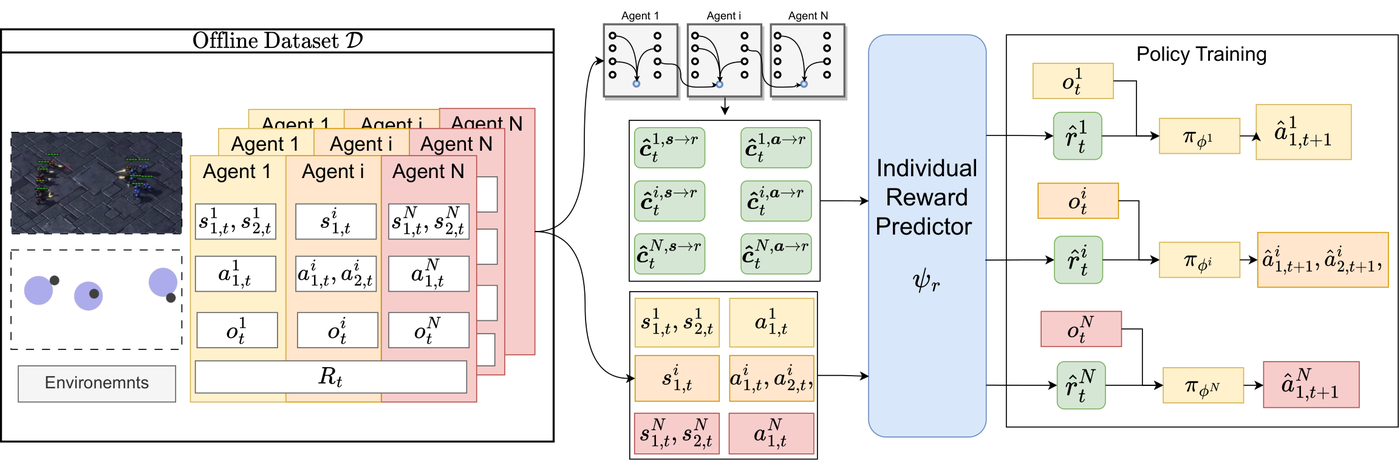
In reinforcement learning and MARL, I study policy learning from books (PLFB), human feedback (M3HF), causal credit assignment (MACCA, GRD), and constrained decision-making (MACPO, SMALL).
In language-agent systems, I study how instructions, social interaction, and shared memory shape agent behavior, including instruction relabeling, strategic discussion, mixed-motive generalization, marketplace safety, and context management.
I am currently an Oxford IDAI Fellow working with Dr Adel Bibi and Prof. Philip Torr, and a research intern in the Future AI Group at Microsoft Research Cambridge. I have also visited Carnegie Mellon University with Prof. Fei Fang and worked with Microsoft Research's AI Frontier Group in Redmond.
Research direction
Distilling Policy from Human Knowledge
My research goal is to distill policies from human knowledge. Knowledge can be implicit in reasoning patterns, shaped through direct instruction, preserved in books, and amplified through collective behavior; my papers study how agents can learn from these media to coordinate, adapt, and act safely.

News
| Jul 2026 | Memento has been accepted to COLM 2026! |
|---|---|
| May 2026 | Started a research internship at Microsoft Research Cambridge, focusing on multi-agent LLM communication and coordination. |
| Feb 2026 | Started the Oxford IDAI Fellowship at the University of Oxford, working with Dr Adel Bibi and Prof. Philip Torr. |
| Nov 2025 | SMALL has been accepted to AAAI AIA 2026! See you in Singapore! |
| Sep 2025 | Starting a Research Internship at Microsoft in Redmond, focusing on LLM reasoning |
| Sep 2025 | One Paper has been accepted to NeurIPS2025! |
Experience & Visits

Research Internship, Future AI Group
Microsoft Research Cambridge, Cambridge, UK · May 2026 - present
Working on multi-agent LLM communication, coordination, and collaborative agent behavior.
Oxford IDAI Fellowship
University of Oxford, Oxford, UK · Feb. 2026 - present
Working with Dr Adel Bibi and Prof. Philip Torr on real-time multi-agent LLM anomaly detection and monitoring.
Research Internship, AI Frontier Group
Microsoft Research, Redmond, US · Sep. 2025 - Dec. 2025
Worked with Vaishnavi Shrivastava and Prof. Dimitris Papailiopoulos on LLM pre-training and reasoning.

Visiting Ph.D. Student
Carnegie Mellon University, Pittsburgh, US · Feb. 2025 - Jun. 2025
Visited Prof. Fei Fang's group, working on multi-agent learning and AI for social impact.
Selected Publications
* equal contribution, ✉ corresponding author
-
-
-
-
Oral
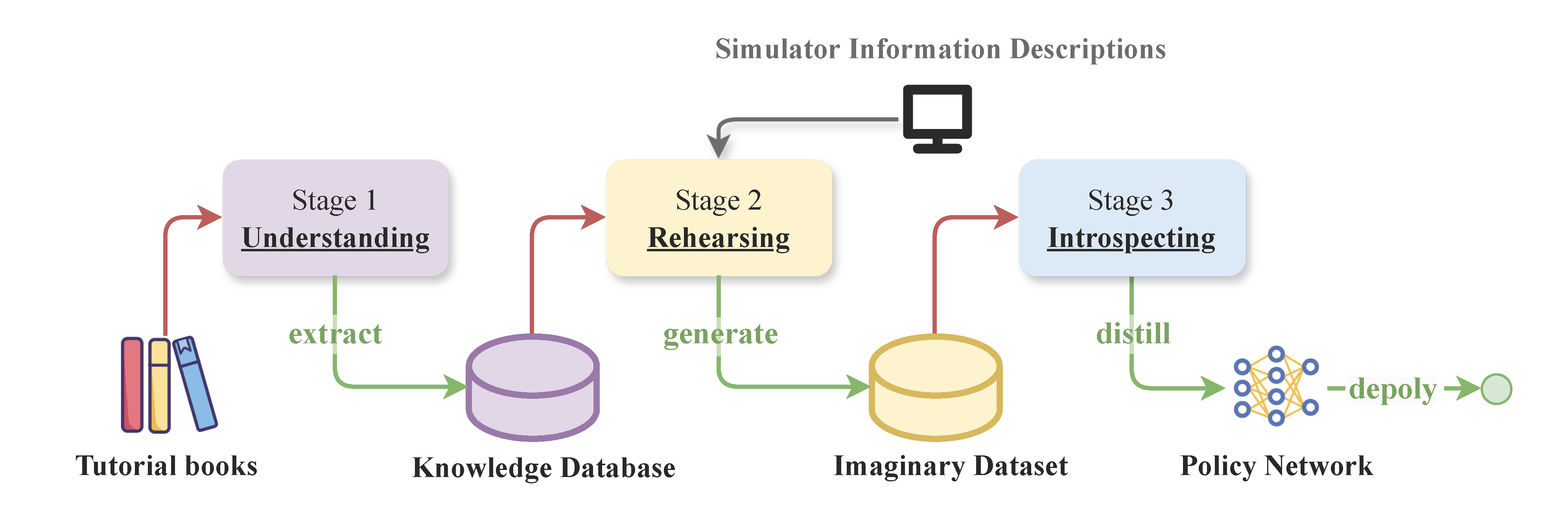
-
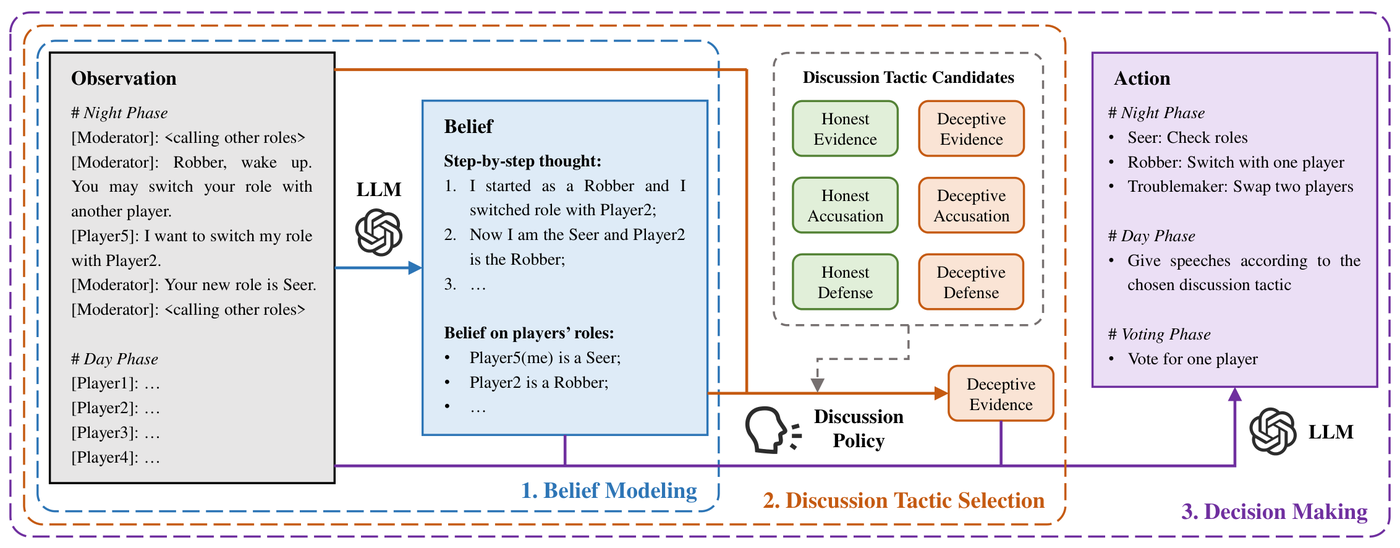
-
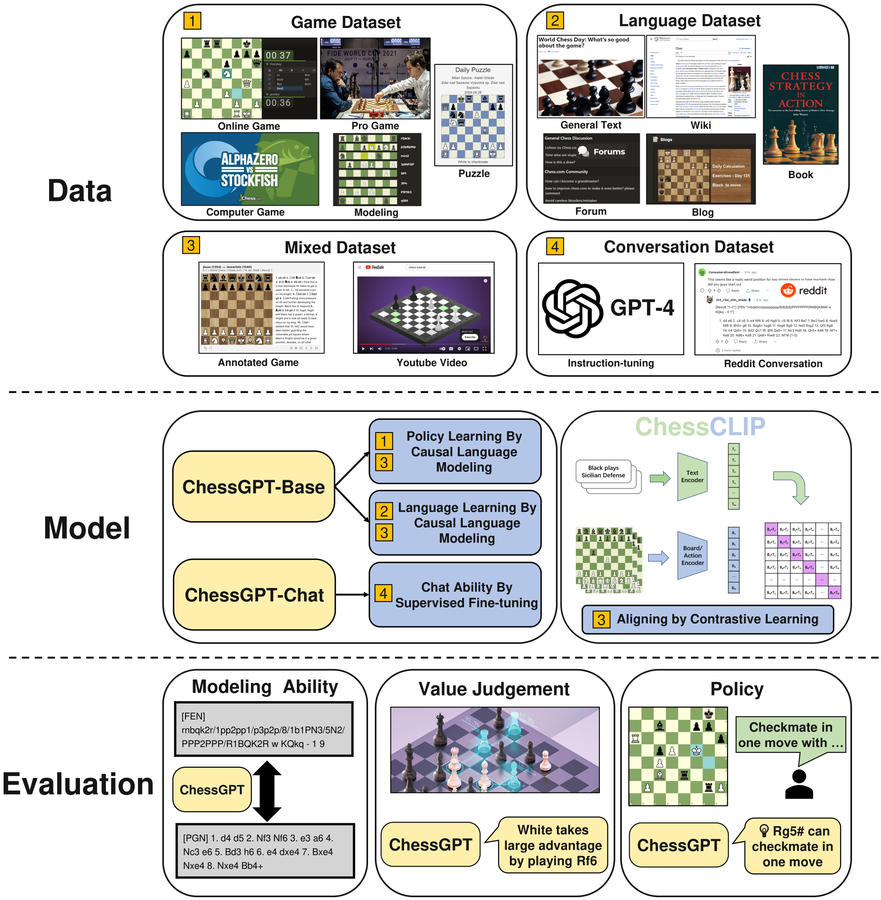
Honors & Teaching
- Honors: Oxford IDAI Fellowship, NeurIPS 2024 Scholar Award, NeurIPS 2024 Oral Presentation
- Teaching: Oxford Machine Learning Summer School, Oxford MLx Fundamentals Summer School, and Optimisation Methods at King’s College London
Professional Services
- Conference reviewer for ICML 2023/24/25/26, NeurIPS 2023/24/25/26, ICLR 2024/25/26, AISTATS 2025/26, and AAMAS 2025/26
- Journal reviewer for IEEE Robotics and Automation Letters, IEEE Transactions on Knowledge and Data Engineering, and IEEE Transactions on Artificial Intelligence